АС Классификатор 5.0 — автоматизация подготовки НСИ
Обзор программного продукта Компании - автоматизированной системы подготовки нормативно-справочной информации (НСИ) "АС Классификатор 5.0".
Глоссарий
- Объект - запись справочника материалов.
- Признак - характеристика объекта, выделяющая его из ряда подобных.
- Иерархическая классификация - последовательное разделение множества объектов на подчиненные группировки (в большинстве случаев осуществляется по отраслевому принципу - в основе Общероссийский Классификатор Продукции).
- Фасетная классификация - параллельное разделение множества объектов на независимые группировки (осуществляется на основании признака и его значения).
- Фасетное описание материала - набор присвоенных значений признаков для конкретного объекта справочника материалов.
- Домен значений признака - ограниченное множество значений конкретного признака.
Система позволяет оперировать со справочными данными, удобна в обращении и выполняет ряд функций, составляющих уникальную методологию Компании по работе со справочником материалов. Отличительным признаком методологии является использование метода комбинирования классификаций: иерархической и фасетной:

Процесс обработки справочных данных состоит из 4х основных этапов (Таблица 1). Для каждого материала определяется иерархический класс (Этап I), а затем отклассифицированному объекту присваивается конкретное значение (или несколько значений) каждого признака в данном иерархическом классе (Этап II), т.е. каждый объект детально обрабатывается и анализируется для унификации исторической информации. После создания фасетного описания генерируются наименования объектов по заданным шаблонам (Этап III). Процедуры контроля качества (Этап IV) проводятся в несколько этапов на различных стадиях готовности справочника. Разумеется, после исправления всех ошибок повторно выполняется генерация наименований (Этап III), чтобы все изменения этапа контроля отразились в конечном продукте - справочнике материалов.
| Этап | Цели | Информационный продукт |
|---|---|---|
| I Классификация | логическое упорядочивание объектов | Структура классов |
| II Создание фасетного описания |
декомпозиция описания объекта на признаки выбор значения каждого признака для данного объекта |
Домен значений признаков |
| III Генерация наименований | унификация наименований | Шаблоны наименований |
| IV Контроль качества |
проверка корректности данных приведение данных в соответствие с требованиями целевой системы |
Таблицы вариантов+Правила Отчеты |
Описанная методология реализуется с помощью инструмента - системы АС Классификатор 5.0. Его задача - автоматизировать основные операции каждого этапа процесса обработки справочника:
Презентация по АС Классификатор 5.0
- Автоматическая классификация исторических данных (Этап I):
а) Благодаря богатому проектному опыту Компании накоплена и постоянно развивается база знаний, на основе которой создается информационный базис для автоматизации процесса классификации исторических данных. На данный момент признана эффективной и используется комбинация из двух методов:
- Фасетный метод . Анализ исторических наименований показывает, что в исходных данных содержится более 70% присвоенных значений признаков - это основная предпосылка фасетного метода автоматической классификации, в котором проверяется вхождение доменных значений признаков в историческое наименование и осуществляется классификация объекта в наиболее вероятный класс из классов-претендентов.
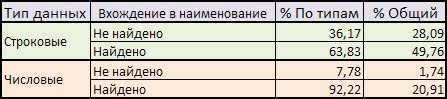
- Метод Q-грамм : Сравниваются подстроки длины Q (Q-граммы) исторического наименования с подстроками (длины Q) из существующей базы знаний отклассифицированных объектов справочника материалов. На основе этого определяется вероятность попадания в класс и осуществляется классификация объекта в наиболее вероятный класс из классов-претендентов. В процессе классификации важно как точное попадание в класс так и попадание в ветку. На данный момент эффективность метода составляет: 77% точных попаданий и 87% попаданий в ветку.
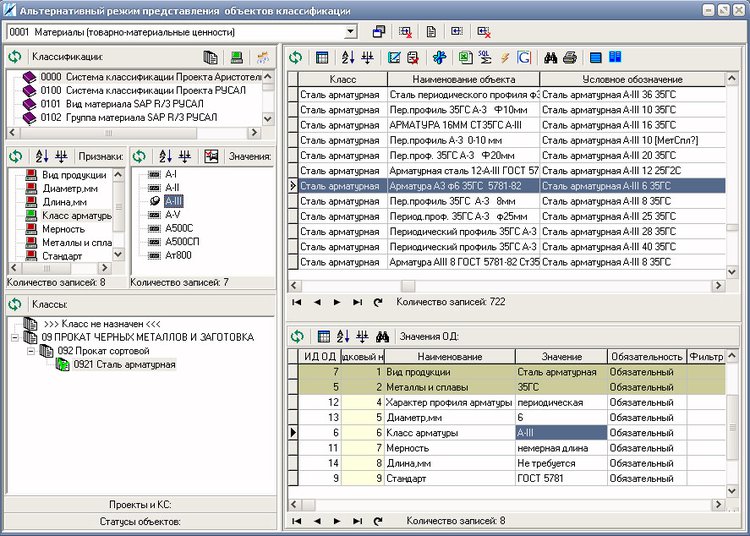
- Просмотр/редактирование присвоенных значений фасетных описаний материалов (Этап II):
а) Реализовано наследование основных свойств класса.
б) В режиме представления объектов удобно организован доступ к основным справочникам и разрезам, необходимым для работы с данными.
в) Доступна множественная прямая и обратная фильтрация по объектам и их атрибутам для удобного поиска.
- Автоматизация процесса создания фасетного описания материала (Этап II):
а) Для автоматического заполнения фасетов имеющейся информацией (из исторического наименования) реализовано распознавание исходных данных при выгрузке в офисные редакторы:
- Процедура распознавания основывается на накопленной базе знаний, эволюционирующей от проекта к проекту.
- Удобный инструмент автоматического разбора строки на компоненты ускоряет работу с историческими данными. Есть возможность задать шаблон исторического наименования, используя регулярные выражения, для адаптации процесса распознавания к исходным данным конкретного проекта.
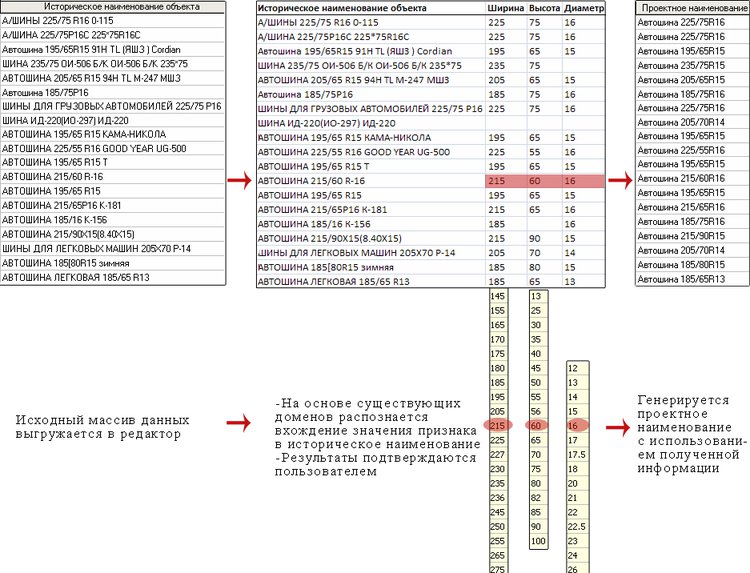
- В процессе распознавания осуществляется исправление обнаруженных ошибок в исходных данных, проводится морфологический разбор и фонетический анализ текста.
б) Для автоматизации процесса дополнения недостающей информацией в системе реализовано доопределение на основе стандартов (ГОСТы, ТУ и т.д.), перенесенных в базу знаний, и на основе статистики:
- доопределяются как однозначно следующие из исторической записи характеристики, так и характеристики, имеющие ряд возможных значений.
- данные, позволяющие дополнять недостающей информацией, также позволяют осуществлять контроль качества данных.
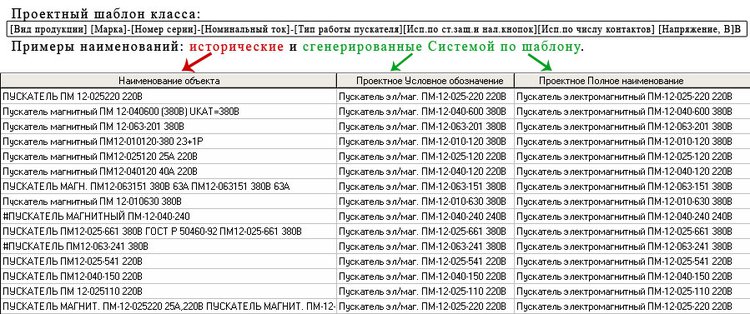
- Генерация наименований на основе созданных шаблонов (Этап III):
а) Гибкий инструмент для создания шаблонов с интуитивно понятным метаязыком позволяет вносить изменения и отражать их в наименованиях в кратчайшие сроки, благодаря фасетной классификации каждого объекта.
б) Реализован индивидуальный подход к формированию наименования материала каждого класса каждого проекта.
в) Результатом применения шаблонов являются наименования, унифицированные в рамках класса.
- Контроль данных с помощью уникальных сервисов, разработанных в АС Классификатор& 5.0 (Этап IV):
а) Методы контроля фасетных описаний материалов:
- Статистические методы: Сервис обзора статистики иллюстрирует частотность использования тех или иных комбинаций значений признаков.
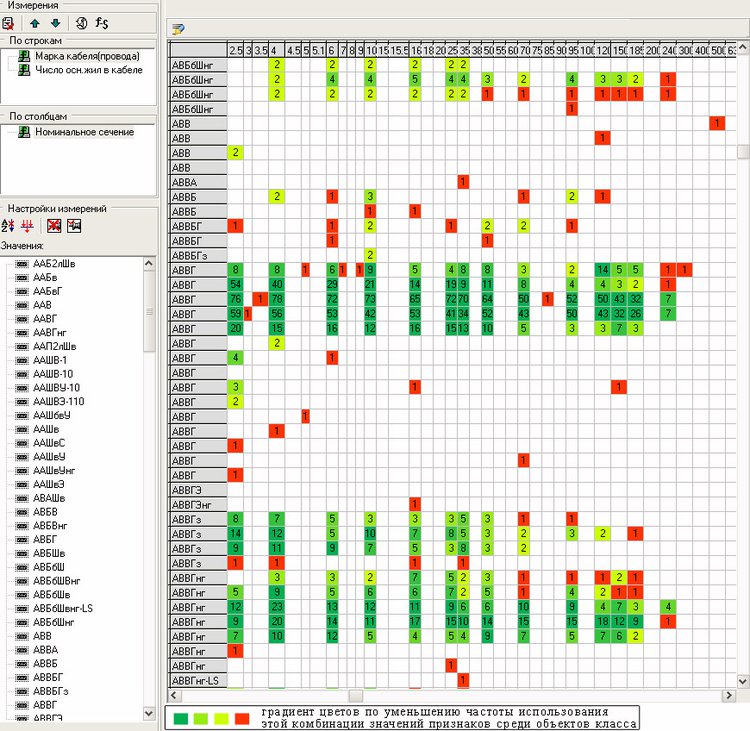
- Статистические методы: Сервис подсчета мер связи между признаками класса позволяет выявлять возможные зависимости среди используемых признаков.
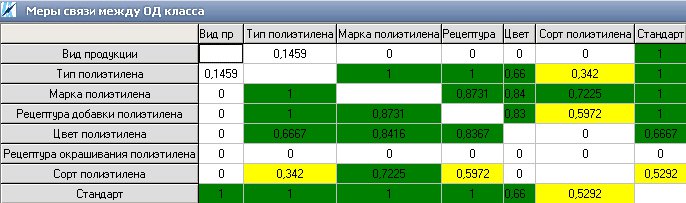
- Стандартизованные методы: Сервис проверки корректности присвоенных значений позволяет контролировать наполняемость базы знаний, а также её корректность и адекватность. Сервис работает на основе таблиц вариантов и правил, создаваемых индивидуально для каждого класса в процессе выполнения проектных работ. Основной принцип-соответствие стандартам (ГОСТы, ТУ и т.д.).

б) Методы улучшения качества данных (позволяют устранять ошибки, восстанавливать целостность базы данных, сохранять принципы ведения мультипроектности, выполнять анализ состояния базы данных и т.д.):
- Аналитический модуль позволяет создавать и использовать отчеты и группы отчетов для контроля качества данных.
- Функциональный модуль позволяет производить автоматические изменения в базе данных, исходя из требований проекта.
- Модули активно используются в ходе проектной деятельности как готовый способ гармонизации данных, их приведения к нужному формату.
- Проектная классификация данных (Этап IV):
а) Классификация материалов конкретного проекта - это адаптированная классификация ООО "Информ-Консалтинг" (необходимо учитывать отраслевые, структурные и профильные особенности бизнеса заказчика). Все изменения отражаются в Проектной классификации, она позволяет осуществлять логическое объединение и декомпозицию классов системы классификации ООО "Информ-Консалтинг".

б) Подготовленный на основе проектной классификации справочник материалов может быть выгружен в формате, соответствующем целевой системе.
{kind=link}